Try Whisper: OpenAI's Speech Recognition Model in 1 Minute
Deepgram has made testing OpenAI's new open-sourced Whisper speech recognition model easy as copy and paste. Try it today!
OpenAI’s newly released “Whisper” speech recognition model has been said to provide accurate transcriptions in multiple languages and even translate them to English. As Deepgram CEO, Scott Stephenson, recently tweeted “OpenAI + Deepgram is all good — rising tide lifts all boats.” We’re stoked to see others are buying into what we’ve been preaching for nearly a decade: end-to-end deep learning is the answer to speech-to-text.
As our team played with Whisper last week, we wanted to make sure as many people as possible could try it with minimal effort. And since we already offer some of the most accurate and performant speech recognition models in the world, why not add another? 😁
Announcing Whisper Multilingual AI Speech Recognition on Deepgram
Last week, we released the Whisper speech recognition model via the Deepgram API. All accounts now have access to the whisper model for free. But, we wanted to make it even easier to try. So, we made it available for people without a Deepgram account. That’s right! You can send files to the API without needing an API key. Try out the shell commands below to see how Whisper performs on your local files or those hosted elsewhere.
Use cURL to Transcribe Local Files with Whisper
You can start testing the Whisper model now by running the snippet below in your terminal.
curl \ --request POST \ --data-binary @youraudio.wav \ --url 'https://api.deepgram.com/v1/listen?model=whisper'Use cURL to Transcribe Remote Files with Whisper
Don’t have an audio file to test? You can also send the URL to a hosted file by changing your request to the code snippet below. You can replace the https://static.deepgram.com/examples/epi.wav URL with a file that you’d like to test against.
curl \ --request POST \ --url 'https://api.deepgram.com/v1/listen?model=whisper' \ --header 'content-type: application/json' \ --data '{"url":"https://static.deepgram.com/examples/epi.wav"}'We even provide several demo files that you can use:
- https://static.deepgram.com/examples/dragons.wav
- https://static.deepgram.com/examples/epi.wav
- https://static.deepgram.com/examples/interview\_speech-analytics.wav
- https://static.deepgram.com/examples/koreanSampleFile.mp3
- https://static.deepgram.com/examples/sofiavergaraspanish.clip.wav
- https://static.deepgram.com/examples/timotheefrench.clip.wav
Try Whisper in Your Browser
You can also test the whisper model in your browser when you signup for a free Deepgram account. Our getting started missions allow you to compare the whisper model to Deepgram models using your own files and/or sample files that we provide.
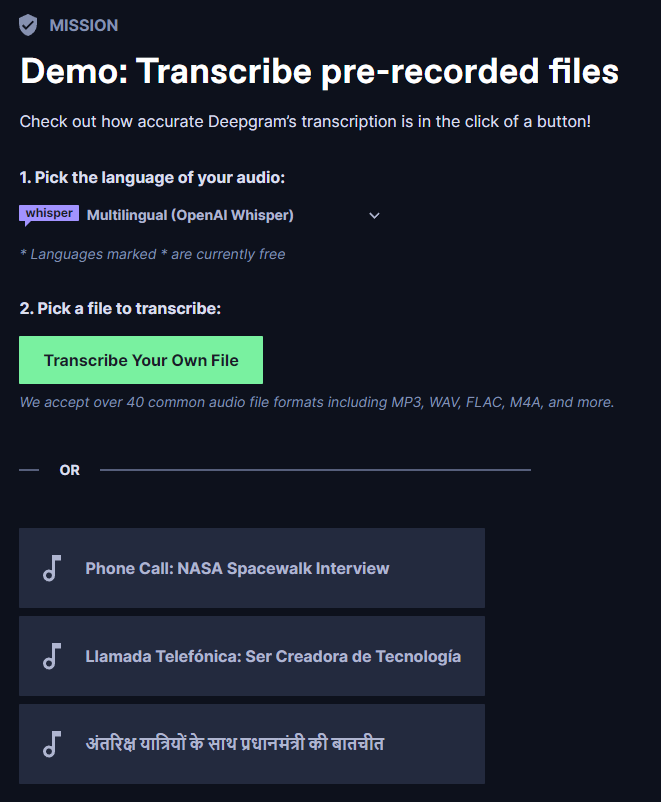
The Final Result
Below is the result of a NASA phone call transcribed with the whisper model.
{ "metadata": { "channels": 1, "created": "Wed, 28 Sep 2022 18:25:08 GMT", "duration": 0, "model_info": { "name": "whisper", "tier": "other", "version": "2022-09-22.0" }, "models": [ "8024132e-81fb-4a77-9377-548cd12c143d" ], "request_id": "826716cc-0c2d-4efe-b6e0-671ca5aea9d5", "sha256": "unsupported", "transaction_key": "deprecated" }, "results": { "channels": [ { "alternatives": [ { "confidence": 0, "transcript": " Yeah, as much as it's worth celebrating the first spacewalk with an all female team, I think many of us are looking forward to it just being normal. And I think if it signifies anything, it is to honor the women who came before us, who were skilled and qualified and didn't get the same opportunities that we have today.", "words": [ { "confidence": 0, "end": 0, "punctuated_word": "Yeah,", "start": 0, "word": "yeah" }, { "confidence": 0, "end": 0, "punctuated_word": "as", "start": 0, "word": "as" }, { "confidence": 0, "end": 0, "punctuated_word": "much", "start": 0, "word": "much" }, { "confidence": 0, "end": 0, "punctuated_word": "as", "start": 0, "word": "as" }, { "confidence": 0, "end": 0, "punctuated_word": "it's", "start": 0, "word": "its" }, { "confidence": 0, "end": 0, "punctuated_word": "worth", "start": 0, "word": "worth" }, { "confidence": 0, "end": 0, "punctuated_word": "celebrating", "start": 0, "word": "celebrating" }, { "confidence": 0, "end": 0, "punctuated_word": "the", "start": 0, "word": "the" }, { "confidence": 0, "end": 0, "punctuated_word": "first", "start": 0, "word": "first" }, { "confidence": 0, "end": 0, "punctuated_word": "spacewalk", "start": 0, "word": "spacewalk" }, { "confidence": 0, "end": 0, "punctuated_word": "with", "start": 0, "word": "with" }, { "confidence": 0, "end": 0, "punctuated_word": "an", "start": 0, "word": "an" }, { "confidence": 0, "end": 0, "punctuated_word": "all", "start": 0, "word": "all" }, { "confidence": 0, "end": 0, "punctuated_word": "female", "start": 0, "word": "female" }, { "confidence": 0, "end": 0, "punctuated_word": "team,", "start": 0, "word": "team" }, { "confidence": 0, "end": 0, "punctuated_word": "I", "start": 0, "word": "i" }, { "confidence": 0, "end": 0, "punctuated_word": "think", "start": 0, "word": "think" }, { "confidence": 0, "end": 0, "punctuated_word": "many", "start": 0, "word": "many" }, { "confidence": 0, "end": 0, "punctuated_word": "of", "start": 0, "word": "of" }, { "confidence": 0, "end": 0, "punctuated_word": "us", "start": 0, "word": "us" }, { "confidence": 0, "end": 0, "punctuated_word": "are", "start": 0, "word": "are" }, { "confidence": 0, "end": 0, "punctuated_word": "looking", "start": 0, "word": "looking" }, { "confidence": 0, "end": 0, "punctuated_word": "forward", "start": 0, "word": "forward" }, { "confidence": 0, "end": 0, "punctuated_word": "to", "start": 0, "word": "to" }, { "confidence": 0, "end": 0, "punctuated_word": "it", "start": 0, "word": "it" }, { "confidence": 0, "end": 0, "punctuated_word": "just", "start": 0, "word": "just" }, { "confidence": 0, "end": 0, "punctuated_word": "being", "start": 0, "word": "being" }, { "confidence": 0, "end": 0, "punctuated_word": "normal.", "start": 0, "word": "normal" }, { "confidence": 0, "end": 0, "punctuated_word": "And", "start": 0, "word": "and" }, { "confidence": 0, "end": 0, "punctuated_word": "I", "start": 0, "word": "i" }, { "confidence": 0, "end": 0, "punctuated_word": "think", "start": 0, "word": "think" }, { "confidence": 0, "end": 0, "punctuated_word": "if", "start": 0, "word": "if" }, { "confidence": 0, "end": 0, "punctuated_word": "it", "start": 0, "word": "it" }, { "confidence": 0, "end": 0, "punctuated_word": "signifies", "start": 0, "word": "signifies" }, { "confidence": 0, "end": 0, "punctuated_word": "anything,", "start": 0, "word": "anything" }, { "confidence": 0, "end": 0, "punctuated_word": "it", "start": 0, "word": "it" }, { "confidence": 0, "end": 0, "punctuated_word": "is", "start": 0, "word": "is" }, { "confidence": 0, "end": 0, "punctuated_word": "to", "start": 0, "word": "to" }, { "confidence": 0, "end": 0, "punctuated_word": "honor", "start": 0, "word": "honor" }, { "confidence": 0, "end": 0, "punctuated_word": "the", "start": 0, "word": "the" }, { "confidence": 0, "end": 0, "punctuated_word": "women", "start": 0, "word": "women" }, { "confidence": 0, "end": 0, "punctuated_word": "who", "start": 0, "word": "who" }, { "confidence": 0, "end": 0, "punctuated_word": "came", "start": 0, "word": "came" }, { "confidence": 0, "end": 0, "punctuated_word": "before", "start": 0, "word": "before" }, { "confidence": 0, "end": 0, "punctuated_word": "us,", "start": 0, "word": "us" }, { "confidence": 0, "end": 0, "punctuated_word": "who", "start": 0, "word": "who" }, { "confidence": 0, "end": 0, "punctuated_word": "were", "start": 0, "word": "were" }, { "confidence": 0, "end": 0, "punctuated_word": "skilled", "start": 0, "word": "skilled" }, { "confidence": 0, "end": 0, "punctuated_word": "and", "start": 0, "word": "and" }, { "confidence": 0, "end": 0, "punctuated_word": "qualified", "start": 0, "word": "qualified" }, { "confidence": 0, "end": 0, "punctuated_word": "and", "start": 0, "word": "and" }, { "confidence": 0, "end": 0, "punctuated_word": "didn't", "start": 0, "word": "didnt" }, { "confidence": 0, "end": 0, "punctuated_word": "get", "start": 0, "word": "get" }, { "confidence": 0, "end": 0, "punctuated_word": "the", "start": 0, "word": "the" }, { "confidence": 0, "end": 0, "punctuated_word": "same", "start": 0, "word": "same" }, { "confidence": 0, "end": 0, "punctuated_word": "opportunities", "start": 0, "word": "opportunities" }, { "confidence": 0, "end": 0, "punctuated_word": "that", "start": 0, "word": "that" }, { "confidence": 0, "end": 0, "punctuated_word": "we", "start": 0, "word": "we" }, { "confidence": 0, "end": 0, "punctuated_word": "have", "start": 0, "word": "have" }, { "confidence": 0, "end": 0, "punctuated_word": "today.", "start": 0, "word": "today" } ] } ] } ] }}There are a few empty data points that stand out, namely confidence, start, and end. The whisper model doesn’t provide that level of detail, so we were forced to provide zero values for them. Comparatively, below is the response using Deepgrams enhanced English model.
{ "metadata": { "transaction_key": "deprecated", "request_id": "146d5bae-5147-468f-9971-dbfcf2e5f152", "sha256": "154e291ecfa8be6ab8343560bcc109008fa7853eb5372533e8efdefc9b504c33", "created": "2022-09-28T18:32:57.088Z", "duration": 25.933313, "channels": 1, "models": [ "125125fb-e391-458e-a227-a60d6426f5d6" ], "model_info": { "125125fb-e391-458e-a227-a60d6426f5d6": { "name": "general-enhanced", "version": "2022-05-18.0", "tier": "enhanced" } } }, "results": { "channels": [ { "alternatives": [ { "transcript": "Yes, as much as it's worth celebrating the first spacewalk with an all female team. I think many of us are looking forward to it just being normal. And I think if it signifies anything, it is to honor the women who came before us, who were skilled and qualified and didn't get the the same opportunities that we have today.", "confidence": 0.99439037, "words": [ { "word": "yes", "start": 0.07996, "end": 0.57996, "confidence": 0.5762918, "punctuated_word": "Yes," }, { "word": "as", "start": 0.91954005, "end": 1.1194401, "confidence": 0.9807544, "punctuated_word": "as" }, { "word": "much", "start": 1.1194401, "end": 1.35932, "confidence": 0.91273105, "punctuated_word": "much" }, { "word": "as", "start": 1.35932, "end": 1.85932, "confidence": 0.98721635, "punctuated_word": "as" }, { "word": "it's", "start": 1.9990001, "end": 2.31884, "confidence": 0.91658056, "punctuated_word": "it's" }, { "word": "worth", "start": 2.31884, "end": 2.7986002, "confidence": 0.9998478, "punctuated_word": "worth" }, { "word": "celebrating", "start": 2.7986002, "end": 3.2986002, "confidence": 0.99984485, "punctuated_word": "celebrating" }, { "word": "the", "start": 4.5177402, "end": 4.67766, "confidence": 0.9901214, "punctuated_word": "the" }, { "word": "first", "start": 4.67766, "end": 5.17766, "confidence": 0.9930007, "punctuated_word": "first" }, { "word": "spacewalk", "start": 5.3173404, "end": 5.8173404, "confidence": 0.9511817, "punctuated_word": "spacewalk" }, { "word": "with", "start": 6.3968, "end": 6.63668, "confidence": 0.99226224, "punctuated_word": "with" }, { "word": "an", "start": 6.63668, "end": 6.7966003, "confidence": 0.99240345, "punctuated_word": "an" }, { "word": "all", "start": 6.7966003, "end": 6.95652, "confidence": 0.97981423, "punctuated_word": "all" }, { "word": "female", "start": 6.95652, "end": 7.3563204, "confidence": 0.9998773, "punctuated_word": "female" }, { "word": "team", "start": 7.3563204, "end": 7.8563204, "confidence": 0.7401077, "punctuated_word": "team." }, { "word": "i", "start": 8.47496, "end": 8.5949, "confidence": 0.99884456, "punctuated_word": "I" }, { "word": "think", "start": 8.5949, "end": 8.874761, "confidence": 0.9998031, "punctuated_word": "think" }, { "word": "many", "start": 8.874761, "end": 9.15462, "confidence": 0.98065513, "punctuated_word": "many" }, { "word": "of", "start": 9.15462, "end": 9.314541, "confidence": 0.999676, "punctuated_word": "of" }, { "word": "us", "start": 9.314541, "end": 9.814541, "confidence": 0.9999099, "punctuated_word": "us" }, { "word": "are", "start": 9.994201, "end": 10.23408, "confidence": 0.9992455, "punctuated_word": "are" }, { "word": "looking", "start": 10.23408, "end": 10.513941, "confidence": 0.9992975, "punctuated_word": "looking" }, { "word": "forward", "start": 10.513941, "end": 10.83378, "confidence": 0.9997292, "punctuated_word": "forward" }, { "word": "to", "start": 10.83378, "end": 10.9937, "confidence": 0.99948406, "punctuated_word": "to" }, { "word": "it", "start": 10.9937, "end": 11.153621, "confidence": 0.9791443, "punctuated_word": "it" }, { "word": "just", "start": 11.153621, "end": 11.3935, "confidence": 0.95780265, "punctuated_word": "just" }, { "word": "being", "start": 11.3935, "end": 11.8935, "confidence": 0.99439037, "punctuated_word": "being" }, { "word": "normal", "start": 11.9932, "end": 12.4932, "confidence": 0.94852126, "punctuated_word": "normal." }, { "word": "and", "start": 12.792801, "end": 13.292801, "confidence": 0.99587005, "punctuated_word": "And" }, { "word": "i", "start": 13.832281, "end": 13.952221, "confidence": 0.97340345, "punctuated_word": "I" }, { "word": "think", "start": 13.952221, "end": 14.23208, "confidence": 0.9995718, "punctuated_word": "think" }, { "word": "if", "start": 14.23208, "end": 14.392, "confidence": 0.9576254, "punctuated_word": "if" }, { "word": "it", "start": 14.392, "end": 14.551921, "confidence": 0.99518657, "punctuated_word": "it" }, { "word": "signifies", "start": 14.551921, "end": 15.051921, "confidence": 0.99909633, "punctuated_word": "signifies" }, { "word": "anything", "start": 15.111641, "end": 15.611641, "confidence": 0.7811873, "punctuated_word": "anything," }, { "word": "it", "start": 15.81996, "end": 16.01986, "confidence": 0.4662335, "punctuated_word": "it" }, { "word": "is", "start": 16.01986, "end": 16.51986, "confidence": 0.9992107, "punctuated_word": "is" }, { "word": "to", "start": 16.89942, "end": 17.05934, "confidence": 0.9627232, "punctuated_word": "to" }, { "word": "honor", "start": 17.05934, "end": 17.55934, "confidence": 0.99968433, "punctuated_word": "honor" }, { "word": "the", "start": 17.65904, "end": 17.77898, "confidence": 0.9969616, "punctuated_word": "the" }, { "word": "women", "start": 17.77898, "end": 18.05884, "confidence": 0.64570725, "punctuated_word": "women" }, { "word": "who", "start": 18.05884, "end": 18.21876, "confidence": 0.99748373, "punctuated_word": "who" }, { "word": "came", "start": 18.21876, "end": 18.41866, "confidence": 0.9997577, "punctuated_word": "came" }, { "word": "before", "start": 18.41866, "end": 18.77848, "confidence": 0.99900305, "punctuated_word": "before" }, { "word": "us", "start": 18.77848, "end": 19.27848, "confidence": 0.91114235, "punctuated_word": "us," }, { "word": "who", "start": 19.41816, "end": 19.91816, "confidence": 0.99943566, "punctuated_word": "who" }, { "word": "were", "start": 20.17778, "end": 20.45764, "confidence": 0.99543494, "punctuated_word": "were" }, { "word": "skilled", "start": 20.45764, "end": 20.897419, "confidence": 0.9809511, "punctuated_word": "skilled" }, { "word": "and", "start": 20.897419, "end": 21.09732, "confidence": 0.86443037, "punctuated_word": "and" }, { "word": "qualified", "start": 21.09732, "end": 21.59732, "confidence": 0.9991331, "punctuated_word": "qualified" }, { "word": "and", "start": 22.37668, "end": 22.57658, "confidence": 0.6425459, "punctuated_word": "and" }, { "word": "didn't", "start": 22.57658, "end": 22.85644, "confidence": 0.99605036, "punctuated_word": "didn't" }, { "word": "get", "start": 22.85644, "end": 23.096321, "confidence": 0.99642485, "punctuated_word": "get" }, { "word": "the", "start": 23.096321, "end": 23.49612, "confidence": 0.9819676, "punctuated_word": "the" }, { "word": "the", "start": 23.49612, "end": 23.61606, "confidence": 0.48681125, "punctuated_word": "the" }, { "word": "same", "start": 23.61606, "end": 23.85594, "confidence": 0.9927979, "punctuated_word": "same" }, { "word": "opportunities", "start": 23.85594, "end": 24.35594, "confidence": 0.99927026, "punctuated_word": "opportunities" }, { "word": "that", "start": 24.535599, "end": 24.7355, "confidence": 0.99610835, "punctuated_word": "that" }, { "word": "we", "start": 24.7355, "end": 24.85544, "confidence": 0.9998843, "punctuated_word": "we" }, { "word": "have", "start": 24.85544, "end": 25.05534, "confidence": 0.9996139, "punctuated_word": "have" }, { "word": "today", "start": 25.05534, "end": 25.55534, "confidence": 0.9614277, "punctuated_word": "today." } ] } ] } ] }}Is Whisper Right for Me?
Are you an AI researcher? Sure! Where else can you get your hands on an implemented end-to-end deep-learning modern architecture to play with? As long as you don’t need real-time transcription, whisper can be used for prototyping and experimenting. However, if you need real-time transcription, speed, and/or scalability, whisper is not ready for use today.
Testing the OpenAI Whisper Models
Have you tried using any of the Whisper models since their release? Tell the community about your experience in our GitHub Discussions.